Explorando la Arquitectura de la Base de Datos Oracle
Oracle es un sistema de gestión de base de datos relacional ( RDBMS “Relational Data Base Management System” ), capaz de manejar gran cantidad de datos en un entorno multi-usuario, donde gran cantidad de usuarios pueden acceder a la misma información de forma concurrente.
Componentes de la Arquitectura de la Base de Datos Oracle
Un sistema de base de datos Oracle consta de 2 partes, la base de datos en sí y una instancia de la base de datos. La base de datos consta de estructuras físicas y lógicas, mientras que la instancia consta de estructuras de memoria y de procesos asociados con dicha instancia.
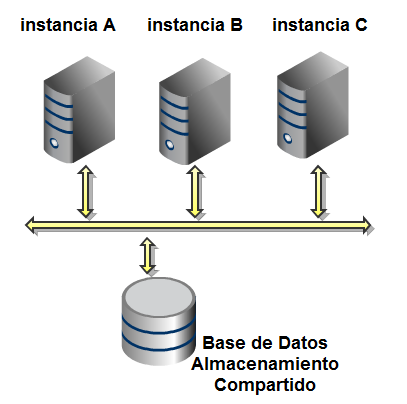
Cada vez que se arranca una instancia, se reserva un espacio de memoria (SGA) y se arrancan una serie de procesos. Después de arrancar la instancia de la base de datos, el software de la base de datos se encarga de asociarla con una base de datos específica, lo que se denomina “montar la base de datos”. A partir de este momento la base de datos está lista para ser abierta, lo que permite a los usuarios conectarse a ella.
Cada instancia de la base de datos está relacionada con solo y solo una base de datos. Una instancia de base de datos no puede ser compartida. En un RAC (Real Application Cluster), normalmente existen varias instancias de base de datos en diferentes servidores que comparten la misma base de datos. En este modelo la misma base de datos está relacionada con varias instancias, y cada instancia únicamente con una base de datos.

Estructuras de Memoria:
Como comentábamos anteriormente, una instancia de base de datos consta de un área de memoria y una serie de procesos que se hacen llamar “procesos de background”. Cada vez que una instancia se levanta, se reserva un área de memoria denominada SGA (System Global Area), y se ejecutan los procesos asociados.
Existen 2 estructuras básicas de memoria en una instancia de base de datos:
- System Global Area (SGA): Esta estructura de memoria es una memoria compartida, ya que tanto el servidor como los procesos de background tienen acceso a dicha área de memoria.
- Program Global Area (PGA): Esta región de memoria es una memoria privada, que solo es accesible por los procesos del servidor o de background. La PGA por tanto no es una memoria compartida, cada proceso tiene su propia PGA.
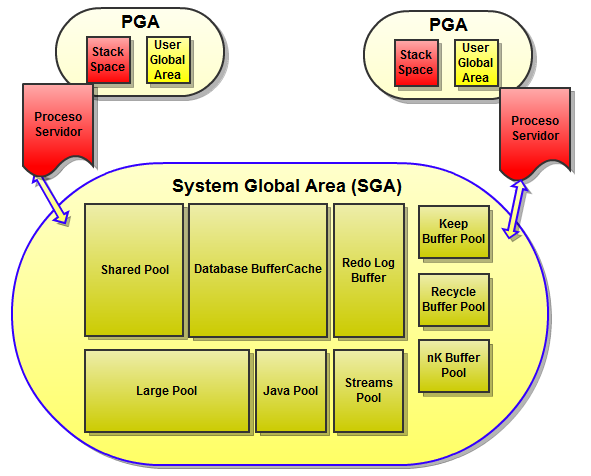
SGA
Database Buffer Cache: Como sabemos Oracle trabaja con bloques de datos (mínima cantidad de información que almacena Oracle y que por defecto suelen ser 8 kb) y no con filas. En esta parte de memoria se almacenan imágenes de los bloques de datos físicos (de disco) utilizados para realizar consultas o que han sido modificados por una sentencia. Siempre que un proceso necesite una determinada información buscará dichos datos en el Database Buffer Cache. Si encuentra la información aquí podrá leer los datos directamente desde memoria (cache hit). Si por lo contrario, el proceso no encuentra la información solicitada en el buffer, tendrá que hacer un acceso a disco y traerse los bloques de datos necesarios a memoria. (cache miss). Cuando Oracle modifica los datos, lo hace directamente sobre el Database Buffer Cache. Estos bloques modificados se denominan bloques sucios o “Dirty Blocks”. La actualización de los bloques en el Database Buffer Cache se realiza por el algoritmo LRU.
Redo Log Buffer: El Redo Log Buffer se podría definir como una bitácora. Esta parte de la memoria actúa como un buffer circular y es donde se registrarán todos los cambios que se produzcan en la base de datos, entendiendo por cambios la ejecución de las sentencias DML (Insert, Update, Delete, Merge) y DDL (Create, Alter, Drop, Truncate). Estas entradas de redo se almacenarán por si fuese necesario una recuperación de la base de datos. Según los procesos vayan haciendo cambios, se irán generando nuevas entradas de redo que se irán escribiendo en la SGA. Estas entradas se irán almacenando de forma secuencial en el buffer y será el proceso de background “Log Writer” (LGWR) el que se encargará de escribir esta información en el fichero físico de log de redo.
Shared Pool: El área de memoria que comprende la Shared Pool contiene la “library cache”, “el data dictionary cache” y el “result cache”.
El “data dictionary cache” es una especie de metadatos de la base de datos, es en definitiva una colección de tablas y vistas que contienen información de la base de datos, sus estructuras y sus usuarios. Es una zona bastante accedida de la base de datos.
Otra área es la “library cache”. Es sin duda otra zona bastante concurrida de la base de datos. Oracle representa cada sentencia SQL que se ejecuta con una zona SQL compartida, con lo que Oracle es capaz de reconocer cuando 2 usuarios ejecutan la misma sentencia, y así poder reutilizar la misma área para ambos usuarios. Esta zona de memoria compartida contiene el plan de ejecución, con lo que Oracle ahorra memoria utilizando la misma área para las sentencias que se ejecutan en múltiples ocasiones.
En la “result cache” se almacenan filas y no bloques. En este área por ejemplo podemos guardar listas de valores muy utilizadas. Para ello tendremos que definir un tipo de Hint especial en nuestras consultas que hagan que los resultados obtenidos se almacenen en esta cache.
Large Pool: Esta zona es opcional. El administrador del sistema puede configurarla siempre que quiera reservar memoria para realizar operaciones de backup o recuperación de la base de datos o consultas en paralelo.
Java Pool: Esta zona se utiliza para almacenar código Java almacenado y datos de la JVM. Es a partir de la versión 8i de Oracle a partir de la cual tenemos disponible esta característica.
Stream Pool: Zona de memoria utilizada para almacenar Oracle Streams. Normalmente se usa en la configuración de Data Guards (Replicaciones de datos, donde a partir de este buffer se irá enviando datos a una base de datos secundaria). A menos que se haya configurado, el tamaño de esta zona de memoria será de 0 kb.
Keep, Recyble Pools: Estas zonas de memorias son similares a la Database Buffer Cache, pero se difieren en que son diseñados para mantener la información más o menos tiempo de lo que la retendría el algoritmo LRU.
Con la infraestructura dinámica de la SGA, el tamaño de los buffers puede ser alterado sin parar la base de datos. La base de datos utiliza una serie de parámetros de inicialización para crear y manejar las estructuras de memoria. La manera más simple de controlar la memoria de la base de datos es dejar a la base de datos que lo haga de forma automática. Para conseguirlo, lo único que tendremos que hacer es establecer 2 parámetros de configuración: MEMORY_TARGET y MEMORY_MAX_TARGET.
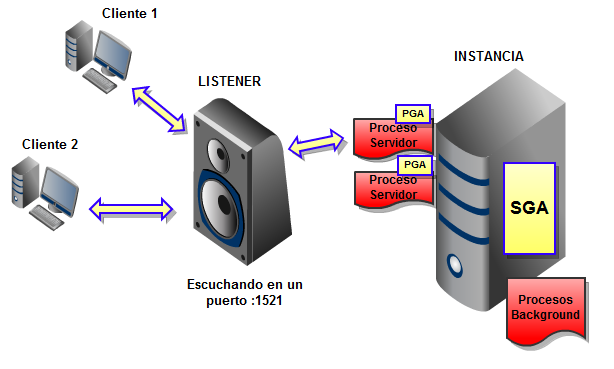
PGA
La Program Global Area, es una región privada de memoria que contiene datos e información de control de los procesos del servidor. Cada proceso tiene su propia PGA, y el acceso a dicha información es totalmente exclusivo.
En un servidor dedicado, cada proceso tendrá un espacio de pila y una zona denominada User Global Area (UGA). En un servidor compartido, en el cual múltiples usuarios comparten el mismo proceso servidor, éste solo tendrá el espacio de pila, mientras que la UGA se almacenará en la SGA.
En la UGA nos encontraremos con la siguiente información:
- Cursores abiertos
- Información de la sesión (quien eres, el rol que tienes…)
- Áreas de trabajo SQL: Consistentes en la realización de varias operaciones SQL, como la ordenación de las consultas (ORDER BY, GROUP BY). En este ejemplo, en el caso de no haber suficiente espacio para llevar a cabo dicha operación esta información será llevada a disco.

{kind=link}