Arquitectura de Procesos de una base de datos Oracle
Si bien el otro día hablaba sobre la arquitectura de una base de datos Oracle, solo tratamos en profundidad la arquitectura de la memoria. Hoy trataré de explicaros la arquitectura de los procesos. En primer lugar vamos a establecer una agrupación de los procesos en 3 grupos:
- Procesos de Usuario: Aplicación o herramienta que se conecta con la base de datos de Oracle
- Procesos de Base de Datos: Donde nos podemos encontrar con los “procesos servidores” (aquellos que conectan las aplicaciones con las instancias de base de datos y que se ejecutan cuando se establece una conexión) y con los “procesos de Background” (Comienzan cuando se arranca una instancia).
- Demonios: Listeners y Grid
Cuando un usuario ejecuta una aplicación, como pudiera ser el “SQL *Plus” o el “PL/SQL Developer”, está haciendo correr lo que se denomina un “proceso de usuario“. Este proceso que puede estar o no en la misma máquina donde se encuentra la base de datos se conectará en primer lugar a un Listener el cual creará un “proceso servidor” que será el encargado de ejecutar los comandos indicados por el “proceso de usuario“. Además de estos procesos, Oracle cuenta con una serie de procesos, llamados “procesos de background” que pertenecen a cada instancia, los cuales interactúan entre ellos y con el sistema operativo para manejar las estructuras de memoria, escribir información en disco, y realizar otro tipo de tareas como veremos más adelante.
Los “procesos servidores” son los encargados de realizar las siguientes tareas:
- Analizar y ejecutar sentecias SQL transmitidas por el proceso de usuario.
- Se encarga de buscar en la Database Buffer Cache (SGA) los bloques necesarios, o de recuperarlos de los “data files” (de disco) si no se encuentran en el buffer.
- Devolver al proceso la información solicitada.
En cuanto a los “procesos de background”, nos podemos encontrar con los siguientes:
- Database write process (DBWn): Se encarga de escribir los bloques sucios del “Database Buffer Cache” a disco.
- Log writer process (LGWR): Se encarga de transferir la información del Redo Log Cache a los ficheros físicos de REDO.
- Checkpoint process (CKPT): Sincroniza el fichero de control con las cabeceras de los data files.
- System monitor process (SMON): Es el monitor del sistema. Monitoriza el sistema, recupera la instancia si fuera necesario.
- Process monitor process (PMON): Es el monitor de procesos. Controla las sesiones, mata las sesiones que considera, y se encarga del registro dinámico del Listener.
- Recoverer process (RECO)
- Job queue coordinator (CJQ0)
- Job slave processes (Jnnn)
- Archiver processes (ARCn)
- Queue monitor processes (QMNn)
En algunos sistemas es possible que nos encontremos con otros más “procesos de background”, sobre todo si hablamos de sistemas configurados en RAC. Podemos obtener más información de los procesos consultando la vista V$BGPROCESS. Algunos de estos procesos se arrancan nada más arrancarse la instancia mientras que otros se arrancan según sean necesarios.
Database Writer Process
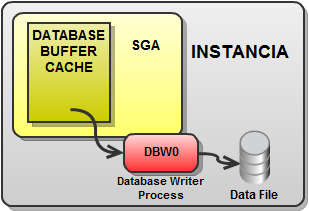 Este proceso se encarga de escribir los bloques sucios (“dirty blocks”) del Database Buffer Cache a disco. Aunque en la mayoría de las ocasiones un único proceso DBW0 es suficiente, se pueden configurar varios DBWn (DBW1.. DBW9 y DBWa..DBWz) para mejorar el rendimiento.
Este proceso se encarga de escribir los bloques sucios (“dirty blocks”) del Database Buffer Cache a disco. Aunque en la mayoría de las ocasiones un único proceso DBW0 es suficiente, se pueden configurar varios DBWn (DBW1.. DBW9 y DBWa..DBWz) para mejorar el rendimiento.
El parámetro de inicialización “DB_WRITER_PROCESSES” indica el número de procesos DBWn. El número máximo son 36. Si no se indica nada, Oracle determina el número de procesos basado en el número de CPUs.
Log Writer Process (LGWR)
El proceso “Log Writer”, es el encargado de transferir la información de los registros del Redo Log Cache a los ficheros físicos de REDO. Este proceso se encarga de escribir las entradas a disco lo suficientemente rápido para asegurar que siempre hay espacio en el buffer. El LGWR escribe a disco en los siguientes casos:
- Cuando se produce un COMMIT
- Cuando se llena 1/3 el buffer de redo (aunque no se hayan confirmado los registros)
- Cada 3 segundos
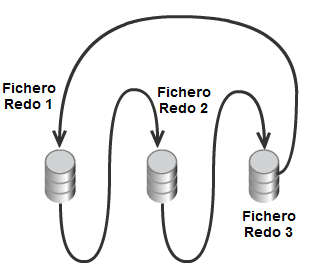
Como vemos en la imagen anexa, hay 3 grupos de ficheros de Redo. En primer lugar se empieza guardando los registros del buffer de Redo Log en el primer grupo de ficheros de logs hasta que éste grupo se llena, momento en el cual se empiezan a guardar los registros en el segundo grupo, para luego continuar en el tercer grupo. Al llenarse este último se vuelven a escribir los registros en el primer grupo de ficheros, funcionando este sistema como un buffer circular.
Si la base de datos se encuentra en modo Archiver, cuando se llena un grupo de ficheros de Redo Log, éste es archivado, con lo que no perderemos la información. El respaldo de los ficheros de Redo puede configurarse para ser almacenados en hasta 10 lugares distintos. Se recomienda tener la base de datos en modo Archiver para base de datos en producción, no tanto para base de datos de desarrollo.
System Monitor Process (SMON)
El proceso SMON es el encargado de recuperar la instancia si fuera necesario. El SMON es el supervisor del sistema y se encarga de todas las recuperaciones que sean necesarias durante el arranque. Esto puede ser necesario si la base de datos se paró inesperadamente por fallo físico por ejemplo. Realiza la recuperación de la instancia a partir de los ficheros Redo Log y se despierta cada poco tiempo para comprobar si debe intervenir.
Process Monitor Process (PMON)
Este proceso es el denominado “monitor de procesos”. Se encarga de restaurar las transacciones que no validadas de los procesos de usuario que abortan, liberando los bloqueos y los recursos. Al igual que SMON, este proceso se despierta regularmente cada poco tiempo para comprobar si debe intervenir.
Archiver Processes (ARCn)
Los procesos ARCn copian la información de los ficheros de Redo Log a los dispositivos de almacenamiento configurados después de que un grupo de ficheros de Redo se haya llenado (haya ocurrido un switch). Los procesos ARCn solo están presentes si la base de datos se encuentra en modo ARCHIVELOG. Si se van a gestionar distintos destinos para los ficheros de archivado, será convenienten tener un procesos asociado a cada uno de los destinos. Por defecto siempre existen 4 procesos ARCn.
Checkpoint Process(CKPT)
Este proceso escribe en los ficheros de control los checkpoints. Estos puntos de sincronización son referencias al estado coherente de todos los ficheros de la base de datos en un instante determinado.
